1. 웹 페이지 크롤링
[ 웹 페이지 추출 ]
- 추출 시 HTTP 헤더와 HTML의 meta 기반으로 인코딩 방식을 판별 필요
- 표준 라이브러리 urllib.requst 모듈을 사용해 웹 페이지 추출
-> urlib.requset에 포함된 urlopen() 함수에 url을 지정하면 추출 가능
* 라이브러리 : 다른사람이 만들어 놓은 코드의 집합 (목적에 맞게 사용 )
- HTTP 헤더를 변경 불가, Basic 인증 사용을 위한 복잡한 처리 필요 (urllib 라이브러리 해당)
-> HTTP 헤더 변경 및 Basic 인증을 위해 urllib 대신 Request 모듈 사용 필요
- urllib를 이용한 웹페이지 추출
from urllib.request import urlopen
f = urlopen('http://hanbit.co.kr')
type(f)http.client.HTTPResponse
* urlopen() 함수는 HTTPResponse 자료형의 객체를 반환
f.read()
f.status200
* HTTP 상태코드
200(성공): 서버가 요청을 제대로 처리했다는 뜻
404(실패): 서버는 요청받은 리소스를 찾을 수 없다는 뜻
f.getheader('Content-Type')'text/html; charset=UTF-8'
* 문자코드가 UTF-8
[ 문자코드 다루기 ]
- HTTPResponse.read() 메소드로 추출할 수 있는 본문은 bytes 자료형
b'<!DOCTYPE html>\r\n<html lang="ko">\r\n<head>\r\n<!--[if lte IE 8]>\r\n<script>\r\n location.replace(\'/support/explorer_upgrade.html\');\r\n</script>\r\n<![endif]-->\r\n<meta charset="utf-8"/>\r\n<title>\xed\x95
\x9c\xeb\xb9\x9b\xec\xb6\x9c\xed\x8c\x90\xeb\x84\xa4\xed\x8a\xb8\xec\
x9b\x8c\xed\x81\xac</title>\r\n<link rel="shortcut icon" h
ref="https://www.hanbit.co.kr/images/common/hanbit.ico"> \r\n<meta http-equiv="X-UA-Compatible" content="IE=Edge" />\r\n<meta property="og:type" content="website"/>\r\n<meta property="og:title" content="\xed\x95\x9c\xeb\xb9\x9b\xec\xb6\x9c\xed\x8c\x90\xeb\x84\xa4\xed\x8a\xb8\xec\x9b\x8c\xed\x81\xac"/>\r\n<meta property="og:description" content="\xeb\x8d\x94 \xeb\x84\x93\xec\x9d\x80 \xec\x84\xb8\xec\x83\x81, \xeb\x8d\x94 \xeb\x82\x98\xec\x9d\x80 \xeb\xaf\xb8\xeb\x9e\x98\xeb\xa5\xbc \xec\x9c\x84\xed\x95\x9c \xec\x95\x84\xec\x8b\x9c\xec\x95\x84 \xec\xb6\x9c\xed\x8c\x90 \xeb\x84\xa4\xed\x8a\xb8\xec\x9b\x8c\xed\x81\xac :: \xed\x95\x9c\xeb\xb9\x9b\xeb\xaf\xb8\xeb\x94\x94\xec\x96\xb4, \xed\x95\x9c\xeb\xb9\x9b\xec\x95\x84\xec\xb9\xb4\xeb\x8d\xb0\xeb\xaf\xb8, \xed\x95\x9c\xeb\xb9\x9b\xeb\xb9\x84\xec\xa6\x88, \xed\x95\x9c\xeb\xb9\x9b\xeb\x9d\xbc\xec\x9d\xb4\xed\x94\x84, \xed\x95\x9c\xeb\xb9\x9b\xec\x97\x90\xeb\x93\x80"/>\r\n<meta property="og:image" content="https://www.hanbit.co.kr/images/hanbitpubnet_logo.jpg" />\r\n<meta property="og:url" content="https://hanbit.co.kr/"/>\r\n<link rel="canonical" href="https://hanbit.co.kr/" />\r\n<meta name="keywords" content="\xed\x95\x9c\xeb\xb9\x9b\xeb\xaf\xb8\xeb\x94\x94\xec\x96\xb4,\xed\x95\x9c\xeb\xb9\x9b\xec\x95\x84\xec\xb9\xb4\xeb\x8d\xb0\xeb\xaf\xb8,\xed\x95\x9c\xeb\xb9\x9b\xeb\xb9\x84\xec\xa6\x88,\xed\x95\x9c\xeb\xb9\x9b\xeb\x9d\xbc\xec\x9d\xb4\xed\x94\x84,\xed\x95\x9c\xeb\xb9\x9b\xec\x97\x90\xeb\x93\x80,\xeb\xa6\xac\xec\x96\xbc\xed\x83\x80\xec\x9e\x84,\xeb\x8c\x80\xea\xb4\x80\xec\x84\x9c\xeb\xb9\x84\xec\x8a\xa4,\xec\xb1\x85,\xec\xb6\x9c\xed\x8c\x90\xec\x82\xac,IT\xec\xa0\x84\xeb\xac\xb8\xec\x84\x9c,IT\xed\x99\x9c\xec\x9a\xa9\xec\x84\x9c,\xeb\x8c\x80\xed\x95\x99\xea\xb5\x90\xec\x9e\xac,\xea\xb2\xbd\xec\xa0\x9c\xea\xb2\xbd\xec\x98\x81,\xec\x96\xb4\xeb\xa6\xb0\xec\x9d\xb4/\xec\x9c\xa0\xec\x95\x84,\xec\x8b\xa4\xec\x9a\xa9/\xec\x97\xac\xed\x96\x89,\xec\xa0\x84\xec\x9e\x90\xec\xb1\x85,\xec\x9e\x90\xea\xb2\xa9\xec\xa6\x9d,\xea\xb5\x90\xec\x9c\xa1,\xec\x84\xb8\xeb\xaf\xb8\xeb\x82\x98,\xea\xb0\x95\xec\x9d\x98,ebook,\xec\xa0\x95\xeb\xb3\xb4\xea\xb5\x90\xea\xb3\xbc\xec\x84\x9c" />\r\n<meta name="description" content="\xeb\x8d\x94 \xeb\x84\x93\xec\x9d\x80 \xec\x84\xb8\xec\x83\x81, \xeb\x8d\x94 \xeb\x82\x98\xec\x9d\x80 \xeb\xaf\xb8\xeb\x9e\x98\xeb\xa5\
xbc \xec\x9c\x84\xed\x95\x9c \xec\x95\x84\xec\x8b\x9c\xec\x
- 문자열(str 자료형)로 다루려면 문자 코드를 지정해서 디코딩 필요
ex) 한국어 사이트를 크롤링 시 여러가지 인코딩이 혼합되어 있을 수 있음 -> HTTP 헤더를 참조해 적절한 인코딩 방식으로 디코딩 필요
[ 문자코드 다루기 ]
- HTTP응답의 Content-Type 헤더를 참조하면 해당 페이지 인코딩 방식 확인 가능
- 한국어가 포함된 페이지의 일반적인 Content-type 헤더
- text/html
- text/html; charset=UTF-8
- text/html; charset=EUC-KR
- UTF-8과 EUC-KR이 해당 페이지의 인코딩 방식
(인코딩이 명시되어 있지 않으면 UTF-8 인코딩으로 간주)
- HTTPMessage 객체의 get_content_charset() 메소드를 사용해 인코딩 추출 가능
[ HTTP 헤더에서 인코딩 방식 추출 ]
import sys
from urllib.request import urlopen
f = urlopen('http://www.hanbit.co.kr/store/books/full_book_list.html')
encoding = f.info().get_content_charset(failobj="utf-8")HTTP 헤더를 기반으로 인코딩 방식을 추출
(명시되어 있지 않을 경우 utf-8을 사용)
# 인코딩 방식을 표준 오류에 출력
print('encoding:', encoding)encoding: utf-8
text = f.read().decode(encoding)추출한 인코딩 방식으로 디코딩
(UTF-8)
print(text)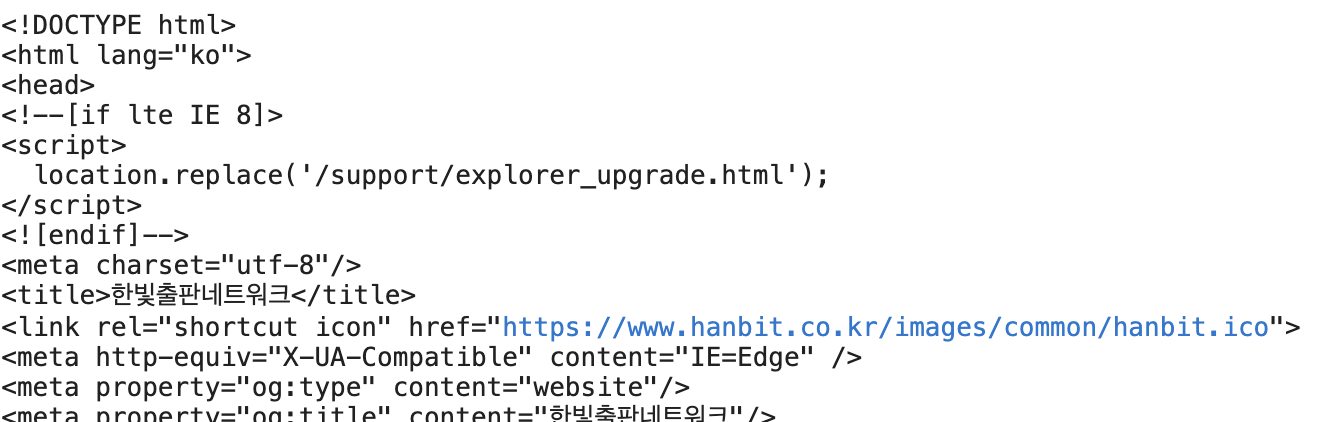
[ meta 태그에서 인코딩 방식 추출 ]
- 웹 서버 설정에 따라 HTTP 헤더의 Content-Type 인코딩과 실제 사용되고 있는 인코딩 형식이 다를 수 있음
- 브라우저는 HTML 내부의 meta 태그 또는 응답 본문의 바이트열 확인을 통해 최종 인코딩 방식 결정 및 화면 출력
- 디코딩 처리중 UnicodeDecodeError 발생 시 이러한 방식으로 구현 가능
- HTML meta에 명시되는 인코딩 형식
<meta charset="UTF-8">

<meta http-equiv= "content-type" content= "text/html charset=euc-kr">

import re
import sys
from urllib.requset import urlopen
f = urlopen('http://www.hanbit.co.kr/store/books/full_book_list.html')
bytes_content = f.read()디코딩 되지않은 응답 본문을 bytes_content에 저장
scanned_text = bytes_content[:1024].decode('ascii',errors='replace')charset은 HTML 앞부분에 적혀있는 경우가 많음
-> 앞부분의 1024바이트를 ASCII 문자로 디코딩
ASCII 범위 이외의 문자는 U+FFFD로 변화되어 예외가 발생하지 않음
match = re.search(r'charset=["\']?([\w-]+)', scanned_text)디코딩한 문자열에서(scanned_text) 정규 표현식으로 charset 값을 추출
charset=["\']?([\w-]+)
- ["\']? : " 또는 ' 를 0개 또는 1개 포함
- ([\w-]+) : 영숫자, 문자, 언더바 또는 - 를 1개 이상 포함
따라서 저 코드를 실행하면
charset = "utf-8" 을 얻을 수 있다.
match.group(1)
'utf-8'
if match:
encoding = match.group(1)
else:
encoding = 'utf-8'charset이 명시되어 찾았다면 그 인코딩 값(match.group(1))을 쓰고
없으면 utf-8로 사용
# 추출한 인코딩을 표준 오류에 출력
print('encoding:', encoding, file=sys.stderr)encoding: utf-8
# 추출한 인코딩으로 다시 디코딩
text = bytes_content.decode(encoding)
# 응답 본문을 표준 출력에 출력
print(text)
2. 스크래핑
[ 웹페이지에서 데이터 추출 ]
- 정규 표현식을 이용한 스크래핑은 HTML을 단순한 문자열로 취급해 필요한 정보 추출
-> 마크업되지 않은 웹 페이지도 문자열의 특징을 파악하면 스크래핑 가능
- XML 파서를 이용한 스크래핑은 XML 태그를 분석(파싱)하여 필요한 정보 추출
-> 블로그 또는 뉴스 사이트 정보를 전달하기 위한 RSS와 같이 많은 데이터가 XML 형태로 제공
XML 파서를 사용하면 정규 표현식보다 간단하고 효과적으로 필요한 정보 추출 가능
- HTML을 스크래핑할 때는 HTML 전용 파서가 필요
-> 파이썬의 표준 모듈인 html.parser 모듈을 사용하면 HTML 파싱 가능(복잡한 처리 필요)
lxml 등과 같은 라이브러리를 사용하여 HTML 파싱 필요
* 정규식을 사용하면 HTML, XML 구분없이 스크래핑 가능
[ 정규 표현식을 이용한 스크래핑 ]
- 정규식(Regular expressions, Regex 또는 Regexp) 이란?
특정 검색 패턴(ASCII 또는 유니코드 문자의 시퀀스)에 대한 하나 이상의 일치 항목을 검색
검색된 텍스트로 부터 정보를 추출하는데 매우 유용하게 사용가능한 표현식
-> 유효성 검사에서 문자열 파싱 및 대체, 데이터를 다른 형식으로 변환 및 웹스크래핑에 이르기까지 다양한 응용분야 활용
-> Python, Javascript, Java 등 프로그래밍 언어와 vi, notepad++ 등 텍스트 에디터에 적용 가능
- 정규식 패턴
| 구분 | 표현 | 설명 |
| Anchors | ^start | start로 시작하는 모든 문자열 매칭 |
| end$ | end로 끝나는 문자열과 매칭 | |
| ^start end$ | start end와 정확하게 일치하는 문자열을 매칭 | |
| roar | roar가 들어있는 모든 문자열과 매칭 | |
| Quantifier | abc* | ab 그리고 0개 이상의 c를 포함한 문자열과 매칭 |
| abc+ | ab 그리고 1개 이상의 c를 포함한 문자열과 매칭 | |
| abc? | ab 그리고 0개 또는 1개의 c를 포함한 문자열과 매칭 | |
| abc{2} | ab 그리고 2개의 c를 포함한 문자열과 매칭 | |
| abc{2,} | ab 그리고 2개 이상의 c를 포함한 문자열과 매칭 | |
| abc{2,5} | ab 그리고 2개 이상 5개 이하의 c를 포함한 문자열과 매칭 | |
| a(bc)* | a그리고 0개 이상의 bc를 포함한 문자열과 매칭 | |
| a(bc){2,5} | a 그리고 2개 이상 5개 이하의 bc를 포함한 문자열과 매칭 | |
| OR operator | a(b|c) | a 그리고 b 또는 c를 포함한 문자열과 매칭 |
| a[bc] | a 그리고 b 또는 c를 포함한 문자열과 매칭 | |
| Bracket expressions | [abc] | a 또는 b 또는 c를 포함하는 문자열과 매칭, a|b|c와 동일 |
| [a-c] | a 또는 b 또는 c를 포함하는 문자열과 매칭, a|b|c와 동일 | |
| [0-9]% | 0이상 9이하 숫자 그리고 %문자를 포함한 문자열과 매칭 | |
| [^a-zA-Z] | 영문이 아닌 문자와 매칭, ^문자는 부정표현으로 사용 | |
| Character classes | \d | 모든 숫자와 일치. [0-9]와 동일 |
| \D | \d와 반대. [^0-9]와 동일 | |
| \n | 개행(줄 바꿈) 문자 | |
| \r | 캐리지 리턴, \x0d, \cM ( 그 줄 맨앞 ) | |
| \s | 공백 | |
| \t | 탭 문자 | |
| \w | 영숫자 문자나 언더바 [ a-zA-Z0-9] | |
| \W | \w와반대 [^a-zA-Z0-9] | |
| . | 모든 문자중 하나 | |
| Grouping and capturing | a(bc) | 소괄호는 캡처 그룹을 생성 |
[ XML을 이용한 스크래핑 ]
- RSS(Really Simple Syndication, Rich Site Summary)란?
뉴스나 블로그 등 업데이트가 빈번한 사이트에서 주로 사용하는 콘텐츠 표현 방식
구독자들에게 업데이트된 정보를 용이하게 제공하기 위해 XML 기반으로 정보 표현 및 제공
RSS 서비스를 이용하면 업데이트된 정보를 찾기 위해 홈페이지를 일일히 방문할 필요없이 업데이트 될 때마다 빠르고 편리하게 확인 가능
브라우저에 확장 프로그램으로 제공되기도 함
- 기상청 RSS
https://www.weather.go.kr/weather/lifenindustry/sevice_rss.jsp
RSS > 인터넷 > 서비스 > 생활과 산업 > 날씨 > 기상청
홈 > 생활과 산업 > 서비스 > 인터넷 > RSS |날씨|생활과 산업|서비스|인터넷|RSS
www.weather.go.kr
- 충청남도 지역 중기예보 RSS URL
www.kma.go.kr/weather/forecast/mid-term-rss3.jsp?stnId=133
- RSS 스크래핑
from xml.etree import ElmentTreeXML 파서 라이브러리인 ElementTree 모듈 로드
tree = ElementTree.parse('rss.xml')parse 메소드로 파일 rss.xml 파일 읽기
root = tree.getroot()getroot() 메소드로 XML의 루트 element 추출해 root 변수에 저장
import pandas as pdpandas 라이브러리 로드 (파이썬에서 상당히 많이 사용되는 라이브러리)
2차원 형태의 데이터 구조를 편리하게 다룰 수 있음
데이터프레임_리스트 = []
for item in root.findall('channel/item/description/body/location/data'):
# find() 메서드로 element 탐색, text 속성으로 값을 추출
tm_ef = item.find('tmEf').text
tmn = item.find('tmn').text
tmx = item.find('tmx').text
wf = item.find('wf').text
데이터프레임 = pd.DataFrame({
'일시':[tm_ef],
'최저기온':[tmn],
'최고기온':[tmx],
'날씨':[wf],
})
데이터프레임_리스트.append(데이터프레임)
날씨정보 = pd.concat(데이터프레임_리스트)
날씨정보 찾고자 하는 데이터가 여러개 있기 때문에 for 루프 수행
'/'로 하위 엘리먼트 명시
find() 함수로 값 추출
pd.DataFrame 함수로 Json 형식으로 만들어 데이터 프레임에 넣음
append 함수로 데이터 프레임_리스트에 데이터 프레임을 계속붙여줌
날씨정보 변수에 concat 함수로 데이터프레임_리스트를 붙여줌
날씨정보 출력

'Database & Bigdata > 공공 빅데이터 청년 인턴십' 카테고리의 다른 글
| [ DAY 8 ] 파이썬 크롤러 만들기 (0) | 2020.09.02 |
|---|---|
| [ DAY 7 ] 데이터 저장/스크래핑 프로세스 (0) | 2020.09.01 |
| [DAY 6] Python기초 (0) | 2020.08.31 |
| [DAY 5] R로 배우는 통계 이해 - 회귀와 예측 (0) | 2020.08.28 |
| [DAY 5] R로 배우는 통계 이해 - 통계적 실험과 유의성 검정 (0) | 2020.08.28 |




댓글