[ 파이썬 소개 ]
- 단순한 언어 , 쉬운 문법, 가독성, 간결한 코드
- FLOSS(Free/Libre and Open Source Software)
- 메모리 관리 등이 불필요한 고수준 언어
- 유니코드 지원 (한글 변수 사용 가능 )
- 동적 타이핑 (동적으로 변수 타입이 변형됨)
- 방대한 규모의 라이브러리
- 언어 습득을 위한 진입장벽이 높지 않음
- 머신러닝/딥러닝 분야에서 많이 활용
[ ANACONDA ]
https://www.anaconda.com/products/individual
Anaconda | Individual Edition
Anaconda's open-source Individual Edition is the easiest way to perform Python/R data science and machine learning on a single machine.
www.anaconda.com
Python 기본 개발환경과 여러 패키지들을 쉽게 설치/관리할 수 있는
배포판 Jupytor notebook, Jupyter lab을 대화형 개발/분석 도구 제공
[ Jupyter_lab ]
[ Python Indentation ]
들여쓰기는 함수 몸체, 조건문, 루프, 클래스 등 다양한 코드 블록을 표현
* 탭은 권장하지 않음 스페이스를 이용해 보통 4칸을 권장
a = True
if a: // ':'로 코드 블록 시작을 의미
print("True") // Indentation
else :
print("False")
[ Code Block ]
코드 블록의 시작은 (:) 콜론
들여쓰기를 기준으로 들여쓰기가 없는 곳이 블록의 끝
// Python
a = True
if a:
print("Ture")
print("Ture End ... ")
else :
print("False")
print('End...') // else 코드 블록 외부로 인식
// Java
// 위 파이썬과 동일한 의미의 자바 코드
boolean a= ture;
if(a) {
System.out.println("True");
System.out.println("True End...");
}
else{
System.out.println("False");
}
System.oun.println("End...");
[ Python 연산자 ]
+ : 더하기
ex) 4 + 2 -> 6
- : 빼기
ex) 4 - 2 -> 2
* : 곱하기
ex) 4 * 2 -> 8
** : 제곱
ex) 4 ** 2 -> 16
/ : 몫
ex) 7 / 2 -> 3.5
// : 정수몫
ex) 7 // 2 ->3
% : 나머지
ex) 7 % 2 -> 1
[ Python 주석문 및 표준 출력 ]
# 파이썬 주석문
# 파이썬
# 주석문
'''
파이썬
주석문
'''파이썬 주석 처리 해제 : CTRL + /
- print() 함수 사용
print ('Hello Python World')Hello Python World
print('a',1)a 1
print('a',1,sep=':') // sep로 : 구분자
a : 1
[ Python 변수 ]
- 값을 저장하기 위한 메모리 영역
- 알파벳, 대소문자, 숫자, under bar(_), 한글, 한자 (유니코드를 사용하기 때문에 한글 사용 가능)
- 첫글자 숫자 X
- 공백, 특수문자, 문장 부호 X
- 대소문자 구별
a = 10
b = 5
print(a,b)10 5
a, b = 2, 4
a,b(2,4)
// 일반적인 프로그램 언어의 SWAP
a = 10; b = 5
temp = a
a = b
b=temp
print(a,b)
5 10
// Python의 SWAP
a = 10; b = 5
a,b = b,a
print(a,b)5 10
[ Python 동적 타입 & 객체 ]
price = 1000
rate = 0.05
num_years = 5
type(rate), type(price)(float, int)
price = 1000
rate = 0.05
num_years = 5
price = price * (1+rate)
price1050.0
type("a"), type(1)(str, int)
a = 1
a.bit_length()1
* 객체화해 함수 사용가능
[ Python 문자열 ]
b = "문자열"
b' 문자열 '
c = '''
죽는 날까지 하늘을 우러러
한 점 부끄럼 없기를
잎새에 이는 바람에도
나는 괴로워 했다
'''
c'\n죽는 날까지 하늘을 우러러\n한 점 부끄럼 없기를\n잎새에 이는 바람에도\n나는 괴로워 했다\n'
'파이썬' + 3Error
* 문자형에 숫자형을 더해 오류가 남
d= '파이썬' + str(3)
d'파이썬3'
* 숫자 3을 str()함수로 문자형으로 형변환해 더함
e = '*' * 10
e'**********'
* 문자열을 숫자만큼 반복함
[ Python 문자열 포맷팅 ]
name, age, phone = '홍길동',25,'010-111-2222'
소개 = "이름은 {} 이고, 나이는 {}세 이며, 전화번호는 {} 입니다.".format(name,age,phone)
소개'이름은 홍길동 이고, 나이는 25세 이며, 전화번호는 010-111-2222 입니다.'
* 중괄호는 위치표시나 마찬가지
format 함수 호출
name, age, phone = '홍길동',25,'010-111-2222'
소개 = "이름은 {0} 이고, 나이는 {2}세 이며, 전화번호는 {1} 입니다.".format(name,phone,age)
소개'이름은 홍길동 이고, 나이는 25세 이며, 전화번호는 010-111-2222 입니다.'
* 중괄호안에 파라미터 값의 위치 표시
0 - 파라미터 첫째값, 1 - 파라미터 둘째값 ...
name, age, phone = '홍길동',25,'010-111-2222'
소개 = "이름은 {a} 이고, 나이는 {b}세 이며, 전화번호는 {c} 입니다.".format(c = phone,a = name,b = age)
소개'이름은 홍길동 이고, 나이는 25세 이며, 전화번호는 010-111-2222 입니다.'
* 중괄호안에 변수
파라미터안에 변수 선언
jan, dec = 1,12
print("한 해의 시작은 {:02d}월".format(jan))
print("한 해의 마지막은 {:02d}월".format(dec))한 해의 시작은 01월
한 해의 마지막은 12월
* 2자리 정수형 포맷 ( 빈자리는 0으로 채움 )
val = 123456789
money = "{:,}"
money.format(val)'123,456,789'
* 3자리씩 ,(콤마)로 구분하는 포맷
'{}, {:f}, {:.1f}, {:.2f}, {:.2%}'.format(3, 3, 3, 3.1475, 1/3)'3, 3.000000, 3.0, 3.15, 33.33%'
f : 소수점 (default 6자리)
.1f : 소수점 첫째자리까지
.2f : 소수점 둘째자리까지
.2% : 소수점 둘째자리까지 백분율로 표시
[ Python 문자열 indexing & Slicing]
- Indexing

파이썬에서는 인덱스와 역인덱스가 있음
인덱스는 0부터 (n-1)까지
역인덱스는 -n부터 -1까지
a[0] = 38
a[-1] = 19
a[:5] = 38,21,43,62,19
* a의 0부터 4까지
a[5:] = 62,19
*a의 3부터 n-1까지
- Slicing
문자열 변수 [ start : end -1 : step ]
start :시작 위치
end -1 : 끝 위치
step : 몇 칸씩 건너 뛸지

b[0::2] = 'Hlo ol!'
0(시작)부터 n-1(끝)까지 2칸씩 띄어서
b[::-1] = '!dlrow ,olleH'
건너뛰는값이 음수일때, 기본 시작점은 -1(끝)
b[0::-2] = '!lo olH'
-1(끝)에서부터 -n(처음)까지 두칸씩 띄어서
[ Python 문자열 ]
| 함수명 | 설명 |
| join | 지정된 문자로 문자열들을 연결 |
| split | 지정된 문자로 분할해 리스트로 반환 |
| strip | 지정된 문자열을 제거 |
| replace | 특정 문자열을 지정된 문자열로 대체 |
| startswith | 지정된 문자열로 시작하는지 검사(True, False로 반환) |
| endswitch | 지정된 문자열로 끝나는지 검사(True, False로 반환) |
| count | 특정 문자의 갯수 |
| index | 특정 문자의 위치 Index |
| find | 특정 문자열의 시작 위치 index |
| capitalize | 단어의 첫글자만 대문자로 변환 |
| upper | 모든 문자열을 대문자로 변환 |
| lower | 모든 문자열을 소문자로 변환 |
[ Python 문자열 함수 ]
'-'.join('HelloWorrldPython')'H-e-l-l-o-W-o-r-r-l-d-P-y-t-h-o-n'
'-' 문자열로 join(연결)
'Hello-World-Python'.split('-')['Hello', 'World', 'Python']
'-' 문자열을 기준으로 split(분할)
'서울시 마포구 상암동 1585'.split()['서울시', '마포구', '상암동', '1585']
디폴트값이 공백문자이므로 공백을 기준으로 split(분할)
text = '\t 문자열 정리\n'
text.strip()'문자열 정리'
디폴트값이 공백문자이므로 공백을 strip(제거)
생일 = '2016/08/30'
생일.replace('/','-')'2016-08-30'
'/' 문자열을 '-' 문자열로 replace(대체)
'Hello World Python'.startswith('Hello')True
Hello로 startswith(시작)하는지 검사 (boolean 타입으로 반환)
'Hello World Python'.endswith('Python')False
Python으로 endswith(끝)나는지 검사 (boolean 타입으로 반환)
'Python' in 'Hello World Python'True
'A' in 'B' -> A가 B에 in(속했는지) 검사 (boolean 타입으로 반환)
text = 'Hello World Python'
text.count('o')3
'o' 문자열을 count(갯수세기)
text = 'Hello World Python'
text.index('o')4
'o' 문자열의 시작 index(위치)
text = 'Hello World Python'
text.index('o',5)7
5번째 문자열 이후의 'o'문자열 index(위치)
text = 'Hello World Python'
text.find('Python')12
'Python' 문자열의 시작 index(위치)
text = 'Hello World Python, Welcome to Python World'
text.find('Python',13)31
13번째 문자열 이후의 'Python'문자열 index(위치)
'Hello World'.capitalize()'Hello world'
단어의 첫 글자만 capitalize(대문자)로 변환
'Hello World'.lower()'hello world'
모든 문자열을 lower(소문자)로 변환
'Hello World'.Upper()
'HELLO WORLD'
모든 문자열을 upper(대문자)로 변환
[ Python 조건문 ]
suffix = "png"
if suffix == "htm":
content = "text/html"
elif suffix == "jpg":
content = "image/jpeg"
elif suffix == "png":
content = "image/png"
else:
content = "False"
print(content)image/png
- 관계 연산자
==, !=, >, < 등
- 논리 연산자
and, or, not 등
[ Python 반복문 ]
a = 0
while a<5:
print(a,'반복합니다.')
a += 10 반복합니다.
1 반복합니다.
2 반복합니다.
3 반복합니다.
4 반복합니다.
a가 5보다 작을때까지 반복
for a in range(0,5):
print(a,'반복합니다')0 반복합니다.
1 반복합니다.
2 반복합니다.
3 반복합니다.
4 반복합니다.
a가 (0부터 5) 범위 내이면 반복
list(range(0,5))[0, 1, 2, 3, 4]
0부터 5-1(n-1)까지 리스트 형태로 출력
- Range() 함수
range(start=0, stop, step=1)
start = 시작값
stop = 종료값(n-1에 종료)
step = 한번에 증가되는 값
list(range(10)) : [0,1,2,3,4,5,6,7,8,9]
list(range(0,10) : [0,1,2,3,4,5,6,7,8,9]
list(range(0,10,2) : [0,2,4,6,8]
list(range(1,10,2) : [1,3,5,7,9]
list(range(10,0)) : []
list(range(10,0,-1)) : [10,9,8,7,6,5,4,3,2,1]
* 10부터 1(0+1)까지 역인덱스
list(range(10,0,-2)) : [10,8,6,4,2]
* 10부터 1(0+1)까지 2칸씩 역인덱스
list(range(10,0,-2)) : [10,7,4,1]
* 10부터 1(0+1)까지 3칸씩 역인덱스
num = list(range(1,11))
for i in num:
print (i)1
2
3
4
5
6
7
8
9
10
num에 저장된 값은 [1,2,3,4,5,6,7,8,9,10]
i가 num에 속할때까지 i 출력
num = 3
for i in range(1,10):
answer = num * i
print(f'{num} * {i} = {answer}')3 * 1 = 3
3 * 2 = 6
3 * 3 = 9
3 * 4 = 12
3 * 5 = 15
3 * 6 = 18
3 * 7 = 21
3 * 8 = 24
3 * 9 = 27
문자열 앞에 f를 붙여주면 foramt 함수와 동일한 역할을 함
[ Python 함수 ]
함수는 호출해야 실행되는 Callable Object
def 함수명(parameter) :
def add2(x,y) :
return x+y
add2(3,4)7
더하기 함수
def sqare(x,y):
x = x**2
y = y**3
return x,y
a,b= sqare(2,3)
print (a)
print (b)4
27
x 제곱, y 세제곱 함수
[ Python 자료구조 - List ]
- List
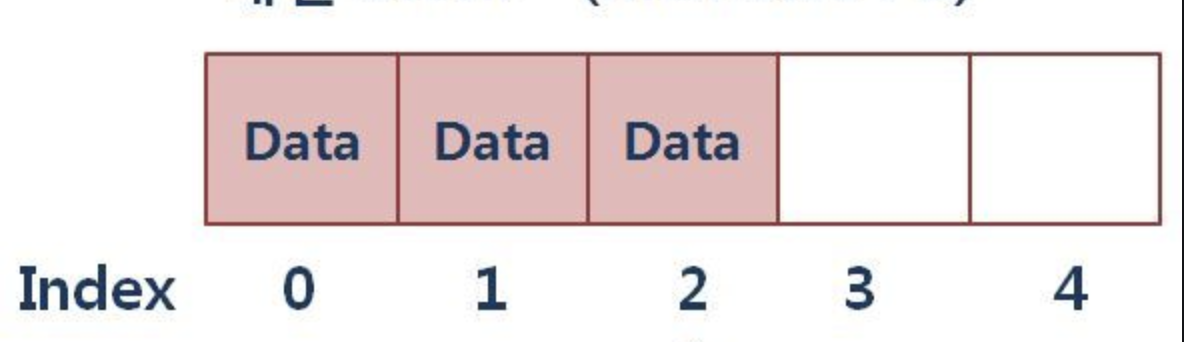
letters = ['A','B','C','D','E','F']
letters
['A', 'B', 'C', 'D', 'E', 'F]
- List 함수
letters.append('a')
letters['A', 'B', 'C', 'D', 'E', 'F', 'a']
append 함수 : 리스트에 'a' 문자열 추가
letters.count('a')1
count 함수 -> 리스트에서 'a' 문자열 숫자 세기
letters.insert(2,'z')
letters['A', 'B', 'z', 'C', 'D', 'E', 'F', 'a']
insert 함수 : 리스트 2번째 인덱스에 'z'문자열 추가
letters.pop(2)'z'
pop 함수 : 리스트 2번째 인덱스에서 추출
letters.remove('a')
letters['A', 'B', 'C', 'D', 'E', 'F']
remove 함수 : 리스트에서 'a' 문자열 삭제
letters.sort(reverse=True)
letters['F', 'E', 'D', 'C', 'B', 'A']
sort 함수 : reverse = True는 내림차순 정렬 (default는 오름차순 정렬)
letters.sort()
letters['A', 'B', 'C', 'D', 'E', 'F']
sort 함수 : reverse = True는 내림차순 정렬 (default는 오름차순 정렬)
- List Indexing & Slicing
letters = ['A', 'B', 'C', 'D', 'E', 'F']
letters[:4] -> ['A', 'B', 'C' , 'D']
* 3(n-1)번째 인덱스까지
letters[ : ] -> ['A', 'B', 'C', 'D' , 'E', 'F']
* 처음부터 끝 인덱스까지
letters[::2] -> ['A', 'C', 'E']
* 처음부터 끝 인덱스까지 2개씩 띄어서
letters[::-1] -> ['F', 'E', 'D', 'C', 'B', 'A']
* 끝부터 처음 인덱스까지 (역인덱스)
- List Comprehension
list(range(1,11))[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
* 1부터 n-1까지 리스트 생성
num10 = list(range(1,11))
[x+1 for x in num10][2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
* 리스트안의 값까지 1씩 증가
for x in num10:
if x % 2 == 0:
print(x)2
4
6
8
10
* 리스트안의 값이 짝수이면 출력
- Tuple
tuple1 = (1,2,3,)
tuple1(1, 2, 3)
* 소괄호 : 튜플
list1 = list(tuple1)
list1[1, 2, 3]
* 대괄호 : 리스트
list1.append(4)
list1[1, 2, 3, 4]
* 대괄호 : 리스트
tuple1 = tuple(list1)
tuple1(1, 2, 3, 4)
* 소괄호 : 튜플
- Dictionary
중간고사 = {
"수학":100,
"영어":90,
}
중간고사{'수학': 100, '영어': 90}
* 중괄호 : Dictionay
중간고사 ['국어'] = 85
중간고사{'수학': 100, '영어': 90, '국어': 85}
국어 점수 추가
중간고사['영어']
90
영어 점수 출력
list(중간고사.keys())['수학', '영어', '국어']
중간고사 key 출력
list(중간고사.values())[100, 90, 85]
중간고사 values 출력
for 과목, 점수 in 중간고사.items():
print('{} 과목점수는 {} 점'.format(과목,점수))수학 과목점수는 100 점
영어 과목점수는 90 점
국어 과목점수는 85 점
items 함수는 Key와 Value의 쌍을 튜플로 묶은 값을 돌려줌(과목,점수)
중간고사['영어'] = 95
중간고사{'수학': 100, '영어': 95, '국어': 85}
value 업데이트
'Database & Bigdata > 공공 빅데이터 청년 인턴십' 카테고리의 다른 글
| [ DAY 7 ] 데이터 저장/스크래핑 프로세스 (0) | 2020.09.01 |
|---|---|
| [ DAY 7 ] 웹 크롤링/스크래핑 (0) | 2020.09.01 |
| [DAY 5] R로 배우는 통계 이해 - 회귀와 예측 (0) | 2020.08.28 |
| [DAY 5] R로 배우는 통계 이해 - 통계적 실험과 유의성 검정 (0) | 2020.08.28 |
| [DAY 4] R로 배우는 통계 이해 - 탐색적 데이터 분석, 데이터 표본 분포 (0) | 2020.08.27 |




댓글